MapReduce - A Simplified Approach to Big Data Processing
Enterprise Architect with over 10 years of experience in financial services, specializing in core banking architecture, investment platforms, and digital transformation across APAC. Adept at defining target state architectures, technology roadmaps, and governance frameworks for large-scale modernization programs. Strong expertise in cloud-native architecture (AWS, Kubernetes), integration design, and data security compliance within regulated environments. Recognized for bridging business strategy and technology execution through C-suite advisory, architecture governance, and cross-functional leadership.
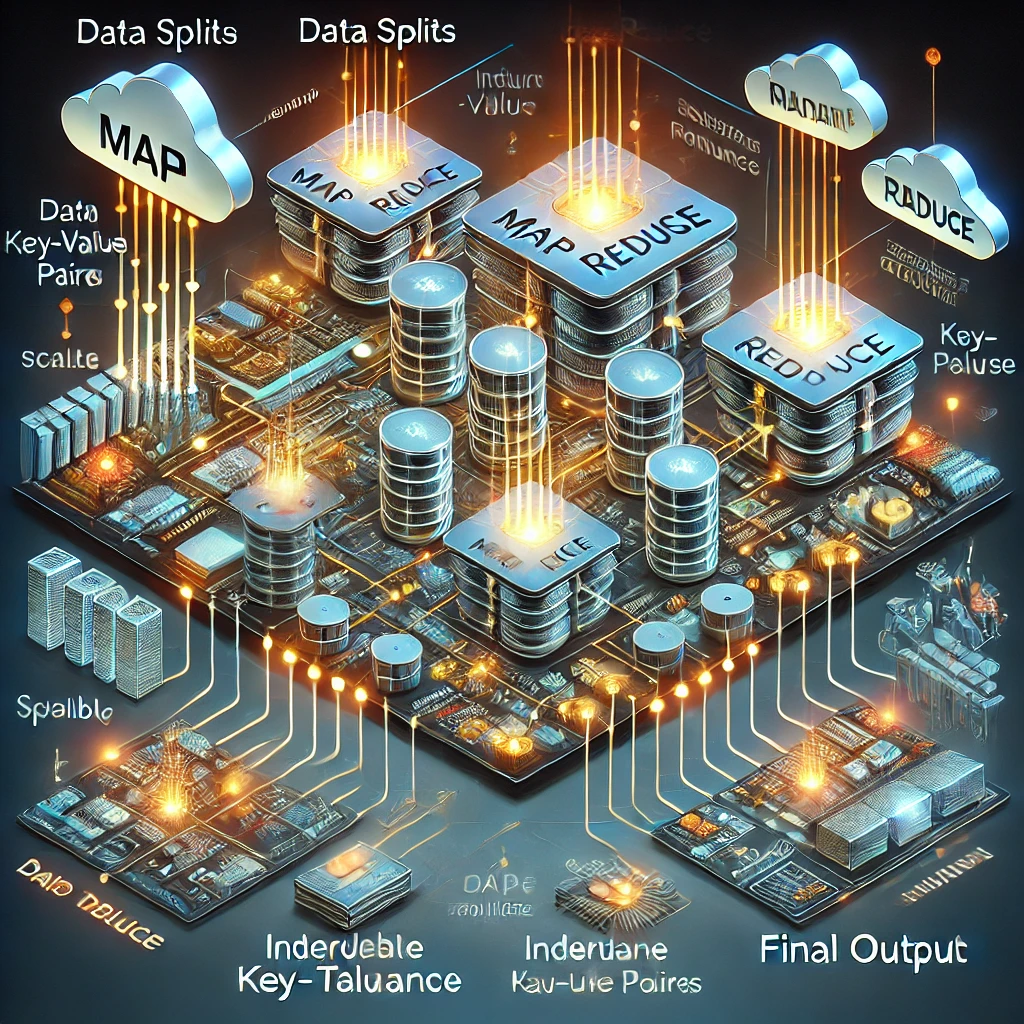
In the era of big data, processing and generating large datasets across distributed systems can be challenging. Enter MapReduce, a programming model that simplifies distributed data processing. Developed at Google by Jeffrey Dean and Sanjay Ghemawat, MapReduce enables scalable and fault-tolerant data handling by abstracting the complexities of parallel computation, data distribution, and fault recovery. Let’s explore how this transformative approach works and why it has been so impactful.
What is MapReduce? MapReduce consists of two core operations:
Map Function: Processes input key/value pairs to generate intermediate key/value pairs.
Reduce Function: Consolidates all values associated with the same intermediate key into a final output.
The model’s simplicity belies its power. By focusing on these two operations, developers can write efficient programs for distributed systems without worrying about low-level details like task scheduling, inter-process communication, or machine failures.
How MapReduce Works The execution of a MapReduce job involves several steps:
Input Splitting: The data is split into chunks, typically 16MB to 64MB, for parallel processing.
Map Phase: Each chunk is processed by worker nodes running the user-defined Map function.
Shuffle and Sort: The intermediate key/value pairs are grouped by key and prepared for reduction.
Reduce Phase: The grouped data is processed by the Reduce function to generate final results.
The MapReduce framework handles complexities like re-executing tasks in case of failures, optimizing data locality to minimize network usage, and balancing workloads dynamically.
Real-World Applications MapReduce is versatile and widely used in industries handling large datasets. Examples include:
Word Count: Counting occurrences of each word in a large document corpus.
Inverted Index: Building searchable indexes for documents, crucial in search engines.
Web Log Analysis: Analyzing URL access frequencies or extracting trends from server logs.
Sorting: Large-scale sorting of terabytes of data, modeled after the TeraSort benchmark.
These use cases demonstrate MapReduce’s ability to handle both data-intensive and computation-intensive tasks efficiently.
Advantages of MapReduce
Scalability: Designed to operate across thousands of machines, processing terabytes of data seamlessly.
Fault Tolerance: Automatically recovers from machine failures by reassigning tasks.
Ease of Use: Abstracts distributed system complexities, enabling non-experts to leverage parallel computing.
Flexibility: Can be adapted to various domains, from indexing to machine learning and beyond.
Efficient Resource Usage: Optimizations like data locality reduce network bandwidth consumption.
Challenges and Limitations While MapReduce is powerful, it has its limitations:
Batch Processing: It’s best suited for batch jobs rather than real-time processing.
I/O Bottleneck: Intermediate results are stored on disk, leading to potential inefficiencies for some workloads.
Limited Expressiveness: The model’s simplicity may not suit all algorithms, especially iterative ones like graph computations.
Impact and Legacy MapReduce revolutionized data processing, inspiring modern frameworks like Apache Hadoop and Apache Spark. Its influence extends beyond its direct applications, shaping how distributed systems are designed and implemented.
Conclusion MapReduce simplifies large-scale data processing by abstracting the complexities of distributed computing. Its blend of simplicity, scalability, and fault tolerance makes it a cornerstone of big data ecosystems. Whether you’re analyzing server logs or building an inverted index, MapReduce offers a robust framework to tackle the challenges of the big data age.